Some Background #
Attack Of The Gooners #
Let's start off with what prompted this experimentation: the insane ramblings of a madwoman addicted to fucking Arcane characters (not me!) on Discord

both prone to slop. I received minimal slop when using the runpod on Steel's test. I remember (no i fucking dont)
Accent 50/50, more so on ARLI's side. Featherless: 45% accent loss. Arli: what the fuck is 100 - 45, i dont know the rest of the percentage
I prefer featherless description more, im being placeboed dont listen to me
featherless listens to lorebook more ive noticed. Cora was mentioned ONLY in the lore book. And she was mentioned the most on feather bird poop penguins side. As well as her traits and personality
Arli was more straight to horny rather than build up
So, obviously there's something different between these two LLM providers.
What The Scallop Is Going On #
Let's compare some details on Featherless's website and ArliAI's website:
Featherless:

Arli:

Well Shit That Was Easy #
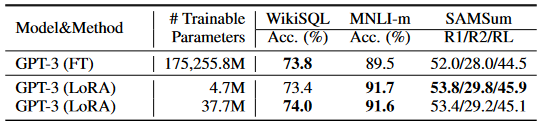
I confirmed with the developers of both, and this is the main difference I can find that would be causing such immense differences. Featherless serves the raw model weights as originally distributed, while Arli manually extracts a LoRA from the model weights from a base model (typically, the original instruct finetune). This has to be the reasoning, right?
The convention is thinking that LoRA shouldn't change the models this much -- in fact, some people, like this ArliAI moderator, have seen people say it actually makes the models better!

Logically, however, this doesn't make much sense. However, to know why it doesn't make any sense you must learn...
WHAT THE FUCK IS A LORA #
Explanation for the math nerds: It's a low rank approximation of a set of delta matrices, added to the base model. You can scroll down now.
Did we get them gone? Good. They're stinky.
Most people consider LoRA to be "a memory efficient finetuning method" -- while this is true, it's a bit misleading, as there are other reasons to use LoRAs.
To explain what a LoRA is, let's imagine you have this specific matrix (also possibly known to you as an N-dimensional array, a tensor, or a vector; effectively, a list of lists of numbers):
[
[4,0,0,0]
[0,3,0,0]
[0,0,2,0]
[0,0,0,1]
]
This is a matrix of rank 4. The rank is, effectively, the maximum amount of independent columns that cannot somehow be derived from one another (at least using math).
In general terms, the rank of a matrix reflects how much unique information is contained in its columns. Lower rank = less information.
Now, what if we want to approximate this matrix?
Of course, we would need another set of rank 4 matrices to get a fully accurate copy, but let's say we don't need it for this use-case -- we only need a rank 2 approximation.
Let's not go too in deep in this process, for the sake of simplicity. Essentially, you would run your matrix through a process of Singular Value Decomposition, which gives you a bunch of new matrices, we do some math and truncation on them, and wahey we get this set of two fun little matrices:
R (shape (4,2)):
[
[2 0 ]
[0 1.7320508]
[0 0 ]
[0 0 ]
]
L (shape (2,4)):
[
[2 0 0 0 ]
[0 1.7320508 0 0 ]
]
And, when we take the product (using fancy matrix multiplication) of these two matrices, we get another 4x4 matrix! Hooray! Just don't look at it:
[
[4,0,0,0]
[0,3,0,0]
[0,0,0,0]
[0,0,0,0]
]
Effectively, we took the most significant values of the matrix, preserved those, and discarded the rest. This is an approximation of the original matrix, and it is smaller, but it is not the same matrix.
This is the principle LoRA works under. It creates a lower rank approximation of a set of model weights (specifically, the difference between a set of base weights and the new weights), and hopes that this won't lose as much accuracy as it might sound like (there are some other ickies to how directly training these adapter weights work but they're irrelevant to this post).
And... it works when finetuned with the lower rank in mind! Somehow.
Where The Car Hits The Curb #
You may notice that I said "it works when finetuned with the lower rank in mind." Gradient descent just be like that!
SVD and rank lowering is not a gradient descending process. It is a pure bruteforce number cruncher. LoRA extraction, as our wonderful ArliAI uses (if you remember them after the math dump), is much more similar to the lossy SVD process than the relatively successful finetuned LoRAs.
So, how do you measure something like this? I sure tried.
The Experimental Setup #
My setup for testing the differences between LoRA extracts and base models (specifically some of the ones hosted on Arli, for comparison's sake) essentially follows the following pipeline:
- Download the base model to test against (in this case, I tried extracting LoRAs against both the smallest model offered on the service (Mistral Nemo 12b Instruct) and one of the largest (Llama 3.3 70b Instruct)
- Download the finetuned model (I ran this on a few, but the two ones we'll go over the exact results of are Sto-vo-kor (thanks Toasty for running the numbers on this one), Bigger Body 12b (for Nemo), and Cu-Mai 70b (for Llama 3.3). Sto-vo-kor is a LoRA finetune on top of Nemo Instruct, so we use it as a baseline -- Bigger Body is a FFT, and Cu-Mai is a merge, both of which will operate and mutate in high rank space)
- Run my comparison script on them, which:
- Takes the delta between the finetuned model and the base model
- Gets the low rank approximation (for 12b,
rank=128; for 70b,rank=64. These values were chosen because they correlate to the ones chosen for ArliAI) - Runs a few metrics on them, primarily their mean squared error and their cosine distance from each-other
- Read the numbers output by the script
The Experiment #
Nemo-based models #
Baseline #
First thing's first: let's verify our thinking on a LoRA finetuned model -- the diff between the two should already be low rank, so the LoRA extraction process shouldn't lose much (if any) detail!
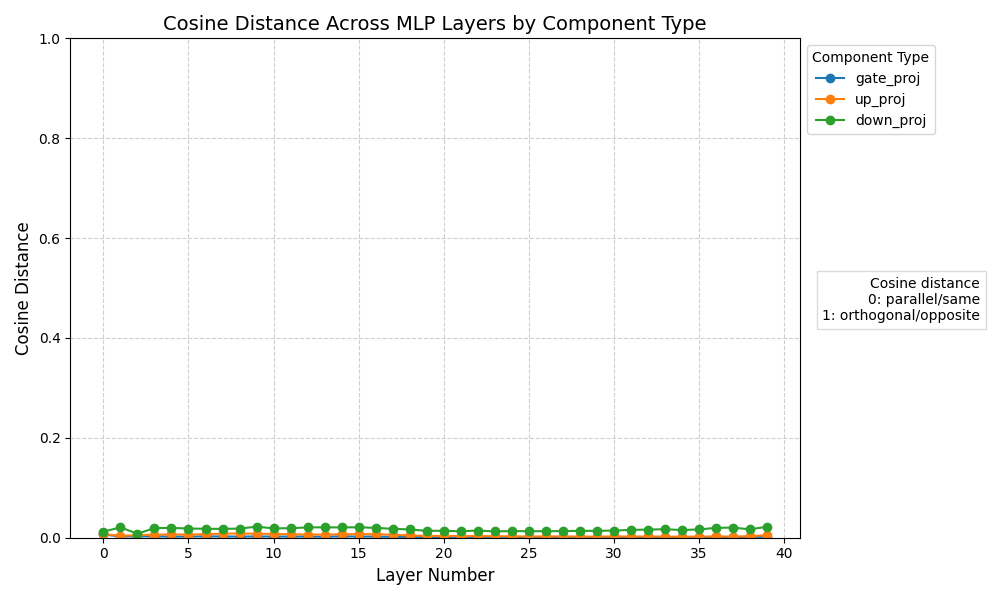
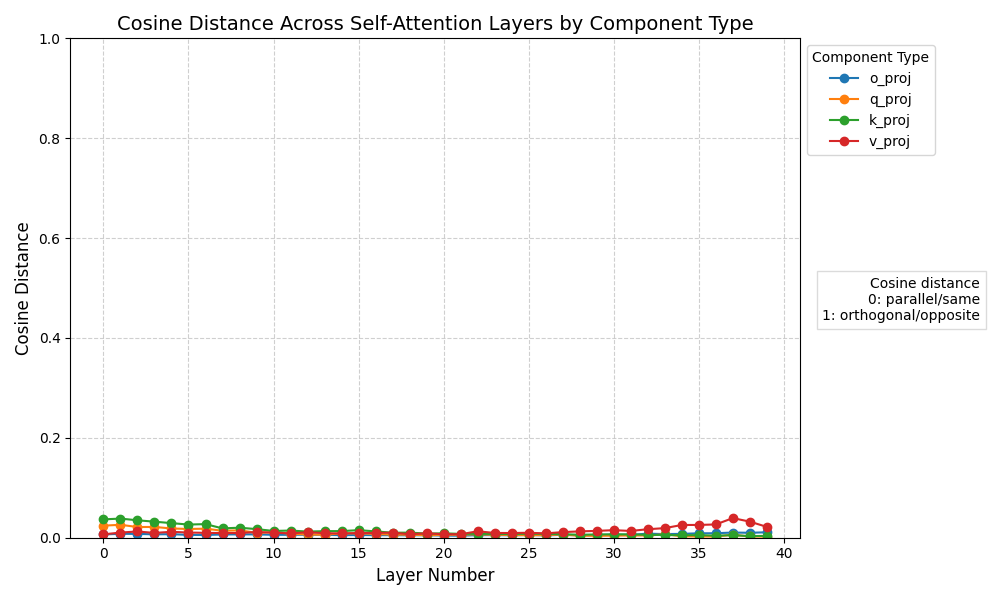
Just as we suspected! The distance is effectively zero, if ever so slightly off (probably not any more than quantization already does to models).
Finetuned model #
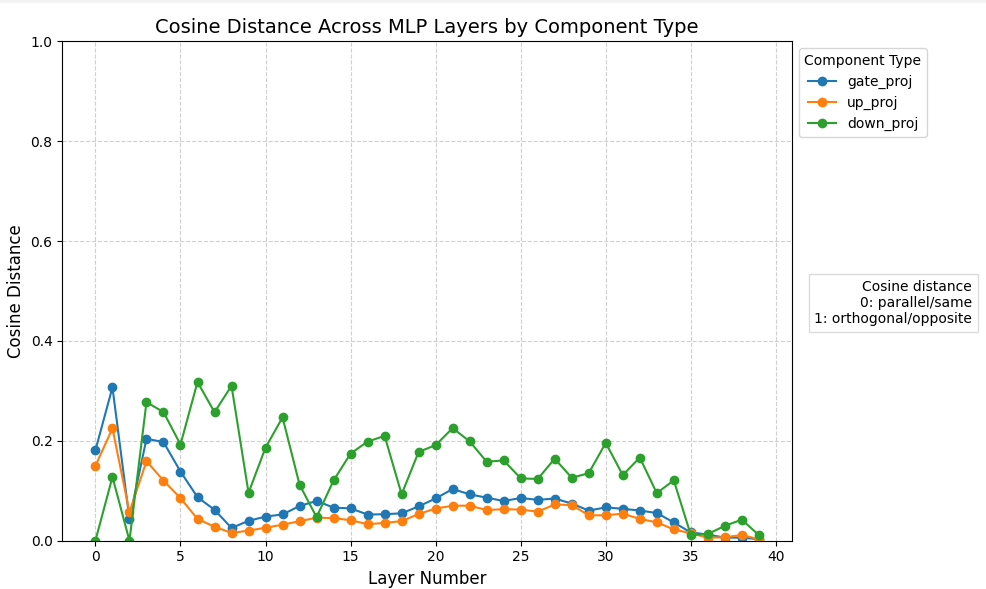
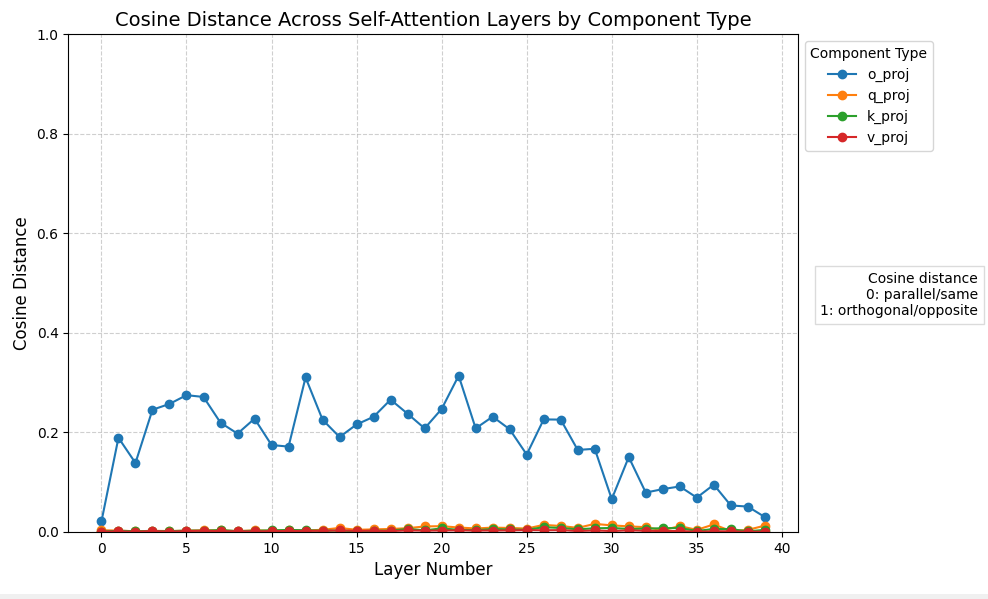
Well, that's interesting.
Some observations here:
- Parts of the MLP layers are, at worst, around 30% different when LoRA extracted from the base model. Other parts, however, appear less sensitive to the rank truncation, and demonstrate far less distance
- The self-attention layers are mostly hardly affected, apart from the output projection (which is the densest layer in a Transformer, so it makes sense)
- There's no obvious correlation between the MLP and self-attention layers regarding spikes in distance
It's not nearly as far off as one might expect if people are complaining about such a difference!
Wait a minute. They were complaining about the 70b models! Let's check those out-
Oh Good Lords (Llama-based models) #
(There is no baseline here, it took way too long for just this one Cu-Mai comparison)
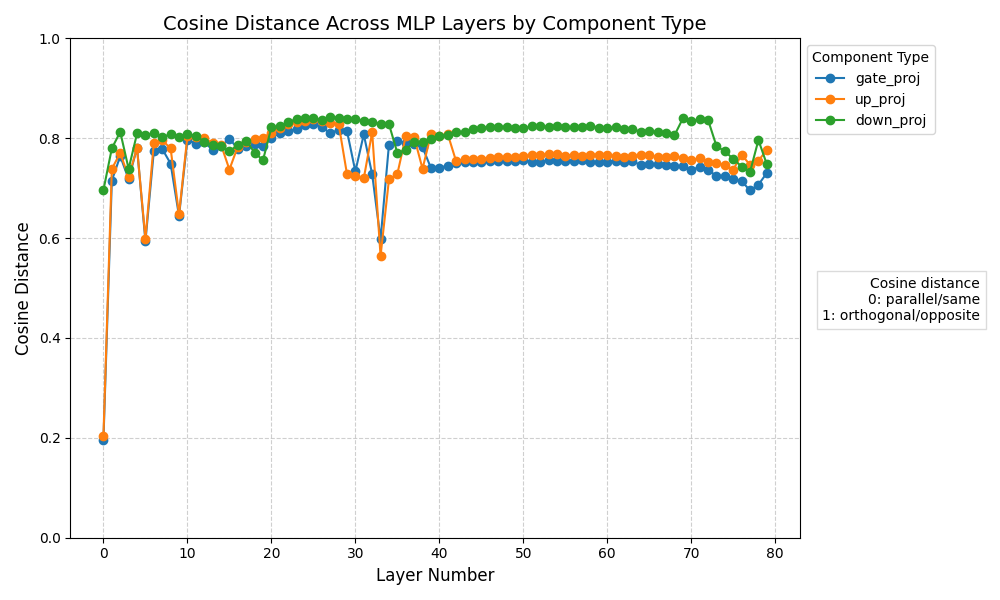
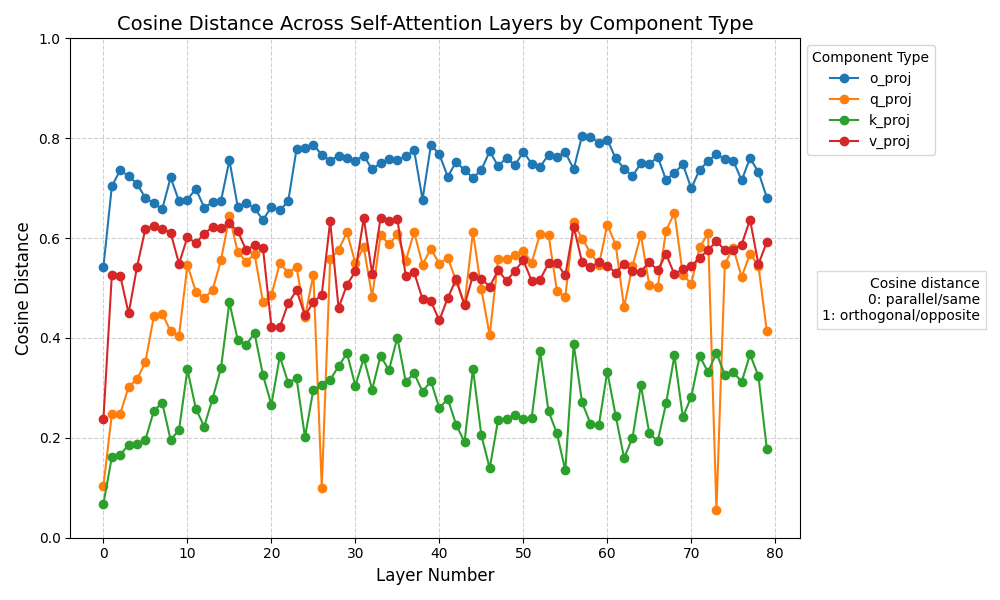
Dear Jesus Harold Christ, that is upwards of an 80% difference in the MLP layers. It is much closer to the 'opposite' matrix than it is the original matrix! Not to mention that the self-attention layers are much further away from the original than they were on the smaller model too!
I can't say anything on what differences something like this would make to model responses, but it's so different numerically that it would be surprising to me if there wasn't pretty noticeable response differences between the original model and the LoRA extraction at this scale.
The Numbers Mason. What Do They Mean #
Effectively, LoRA extraction is very lossy! Moreso on larger models.
More Wordy Conclusion #
- Truncated SVD is not very accurate for LLM matrices
- Qualitative differences are still a more important measurement for determining how different a model actually is, and this post should be taken with a pile of salt
- Further experimentation should probably focus on comparing model outputs statistically (such as looking at the KL divergence of the logits, or doing TFIDF on a batch of results and comparing)
- Would also be worth seeing if higher LoRA ranks still in the realm of servability (such as rank 256 or 512), though this is still far far lower than the real ranks of even 12b models so I don't think it would work very well
On Arli #
Update #
I've talked to Owen, and the website has been changed!
It now states:
We extract a LoRA for each of the finetuned models. This is allows us to host many models by hotswapping LoRAs on the fly as needed while maintaining model behavior similar to the original (but not exactly the same).
Which is much closer to the truth than the original text! :D
I still have problems with some of the rhetoric from some of their Discord members, but it's independent of the service itself, so.
The original is maintained below for posterity.
Original Section #
I don't think Owen (the main person behind Arli) intended to mislead, nor do I think he's intentionally lying about how much the models may be changed from the original. However, I still find some of the advertising on the website to be misleading at best. Take for example this marketing copy we showed above:
We extract high-rank LoRA for the finetuned models. This is allows us to hotswap LoRAs on the fly as needed while maintaining near-lossless performance.
This is just false, and unintentionally misleading at best. It is not remotely "near-lossless" to compress a model with sometimes tens of thousands of ranks down to rank 128 or 64, as we've shown. The tradeoff between model count and model quality is much more nuanced here than this FAQ answer makes it sound.
There's also some other slightly (but not intentionally, I believe!) misleading statements, such as in the model list where it states that hosted finetunes are:
Models finetuned from the base model in the category
This, while technically true, is once again somewhat misleading -- it's not the models themselves, it's the LoRA extraction of them. If some regular user walked up and read that, they wouldn't believe the listed models are different; they'd think that they were getting the same model that any other inference platform uses, which is just not true.
Once again, I don't think Arli is lying or being intentionally misleading. However, I do hope they correct some of the marketing to be more accurate and not fool customers into subscribing to a platform they won't like as much as another.
Appendix A: compare.py #
Please ignore the horrid code. I had some troubles with local CPU memory.
1import gc
2from safetensors.flax import load_file
3#import numpy as np
4#import numpy.linalg as linalg
5import json
6from tqdm import tqdm
7#from scipy.stats import entropy
8#from scipy.spatial.distance import cosine
9import jax
10import jax.numpy as jnp
11import jax.numpy.linalg as jlinalg
12import optax
13
14results = {}
15
16base_files = [
17 # ...
18]
19
20fft_files = [
21 # ...
22]
23
24for fft_file, base_file in zip(fft_files, base_files): # pls be shard aligned
25 gc.collect()
26
27 base = load_file(base_file)
28 fft = load_file(fft_file)
29
30 keys = list(set(base.keys()) & set(fft.keys()))
31
32 # Delete weights not in both models to free memory
33 for key in set(base.keys()) - set(keys):
34 del base[key]
35 for key in set(fft.keys()) - set(keys):
36 del fft[key]
37 gc.collect()
38
39 @jax.jit
40 def get_lossy_svded_diff(diff, rank=64):
41 # Get the SVD of the diff
42 U, S, Vh = jlinalg.svd(diff, full_matrices=False)
43 # Get the lossy SVD of the diff
44 rank = min(rank, min(diff.shape))
45 sqrt_S = jnp.sqrt(jnp.diag(S[:rank]))
46 L = sqrt_S @ Vh[:rank, :]
47 R = U[:, :rank] @ sqrt_S
48 print(diff.shape)
49 print(R.shape, L.shape)
50 return R @ L
51
52 @jax.jit
53 def get_mse(orig, lossy):
54 return jnp.mean((orig - lossy) ** 2)
55
56 @jax.jit
57 def get_cosine_distance(orig, lossy):
58 flat_orig = orig.flatten()
59 flat_lossy = lossy.flatten()
60 return optax.cosine_distance(flat_orig, flat_lossy)
61
62 @jax.jit
63 def get_rank(diff) -> jax.Array:
64 return int(jlinalg.matrix_rank(diff))
65
66 def losses(orig, lossy):
67 mse = get_mse(orig, lossy)
68 cosine_distance = get_cosine_distance(orig, lossy)
69 return {
70 "mse": str(mse),
71 "cosine_distance": str(cosine_distance)
72 }
73
74 def get_results(diff, lossy_diff):
75 return {
76 "loss": losses(diff, lossy_diff),
77 "mean_diff_value": str(jnp.mean(jnp.abs(diff))),
78 "diff_rank": min(diff.shape),
79 #"diff_eff_rank": get_rank(diff).item()
80 }
81
82 diffs = {}
83 lossy_diffs = {}
84
85 # Filter out 1D arrays
86 keys = [key for key in keys if len(base[key].shape) > 1]
87
88 # Filter out embedding and language model head layers
89 keys = [key for key in keys if "embed" not in key and "lm_head" not in key]
90
91 for key in tqdm(keys, desc="Extracting deltas/diffs"):
92 diff = fft[key] - base[key]
93 diffs[key] = diff.astype(jnp.float32)
94 del fft[key]
95 del base[key]
96 gc.collect()
97 gc.collect()
98 gc.collect()
99
100 del fft
101 del base
102
103 for key in tqdm(keys, desc="Getting SVD of diffs"):
104 gc.collect()
105 lossy_diffs[key] = get_lossy_svded_diff(diffs[key])
106
107 for key in tqdm(keys, desc="Calculating loss"):
108 results[key] = get_results(diffs[key], lossy_diffs[key])
109
110 del diffs
111 del lossy_diffs
112
113 print(results)
114 with open("results.json", "w") as f:
115 json.dump(results, f, indent=4)
116
117 gc.collect()
118 gc.collect()
119 gc.collect()
120 gc.collect()
121 gc.collect()